Transaction on TiKV
The previous section introduces the architecture of the transaction engine and several implementation details in TiDB part. This document is mainly about the TiKV part.
As described in the previous section, the distributed transaction coordinator is tidb-server which receives and processes COMMIT query, and the transaction participants involved are tikv-servers.
Transactional Protocol
The RPC interfaces in TiDB are defined in a protobuf file, based on the Percolator model.
These interfaces will be used by the transaction coordinator to drive the whole commit process. For example Prewrite will be used to write the lock record in TiKV:
message PrewriteRequest {
Context context = 1;
// The data to be written to the database.
repeated Mutation mutations = 2;
// The client picks one key to be primary (unrelated to the primary key concept in SQL). This
// key's lock is the source of truth for the state of a transaction. All other locks due to a
// transaction will point to the primary lock.
bytes primary_lock = 3;
// Identifies the transaction being written.
uint64 start_version = 4;
uint64 lock_ttl = 5;
// TiKV can skip some checks, used for speeding up data migration.
bool skip_constraint_check = 6;
// For pessimistic transaction, some mutations don't need to be locked, for example, non-unique index key.
repeated bool is_pessimistic_lock = 7;
// How many keys this transaction involves in this region.
uint64 txn_size = 8;
// For pessimistic transactions only; used to check if a conflict lock is already committed.
uint64 for_update_ts = 9;
// If min_commit_ts > 0, this is a large transaction request, the final commit_ts
// will be inferred from `min_commit_ts`.
uint64 min_commit_ts = 10;
// When async commit is enabled, `secondaries` should be set as the key list of all secondary
// locks if the request prewrites the primary lock.
bool use_async_commit = 11;
repeated bytes secondaries = 12;
// When the transaction involves only one region, it's possible to commit the transaction
// directly with 1PC protocol.
bool try_one_pc = 13;
// The max commit ts is reserved for limiting the commit ts of 1PC or async commit, which can be used to avoid
// inconsistency with schema change.
uint64 max_commit_ts = 14;
}
mutationsare changes made by the transaction.start_versionis the transaction identifier fetched from PD.for_update_tsis used by the pessimistic transactions.try_one_pcfield is used if the transaction is committed usingone-phaseprotocol.use_async_commitandsecondarieswill be used if the transaction is committed in theasync-commitmode.
Besides prewrite request, there are some other important request types:
pessimistic_lockrequest is used to lock a key. Note pessimistic locking happens in the transaction execution phase, for example aselect for updatestatement will need to pessimistically lock the corresponding rows.commitrequest is used to commit a key. After commit the write content is visible to other read or write transactions.check_txn_statusrequest will be used to check the status of a given transaction, so that it could be decided how to process the conflicts.resolverequest will be used to help doing the transaction crash recovery.check_secondary_locksrequest is a special API, it will be used if the commit mode of the transaction isasync-commit.
Transaction Scheduler
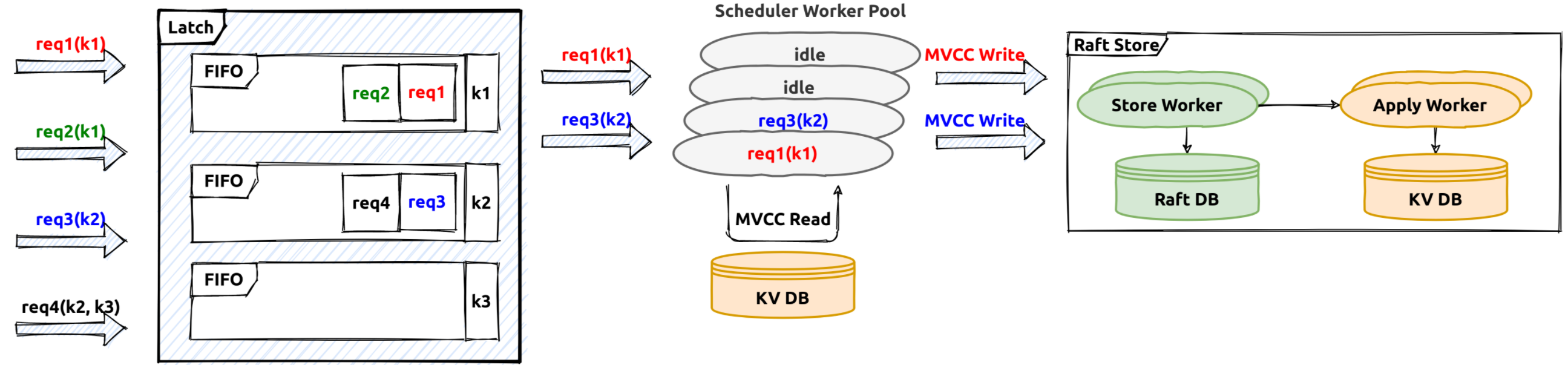
The receiving input transaction requests will be translated into transaction commands. Then the transaction scheduler will handle these transaction commands, it will first try to fetch the needed key latches (latch is used to sequence all the transaction commands on the same key),then try to fetch a storage snapshot for the current transaction processing.
The task will be processed as a future. The future processing is done in the transaction scheduler thread-pool. Usually, there will be some tasks like conflict and constraint checks, write mutation generations. For example, the prewrite request processing will need to check if there is already a conflict lock or a conflict committed write record.
Transaction Log Replication
In TiDB, the key space is split into different ranges or regions. Each region is a raft group and its leader will be responsible for handling its key range related read/write requests.
If the transaction command processing in the transaction scheduler is successful, the generated transaction writes will be written into the raft log engine by the region leaders in raftStore (raft store will be introduced in other documents in details). The work flow is like this:
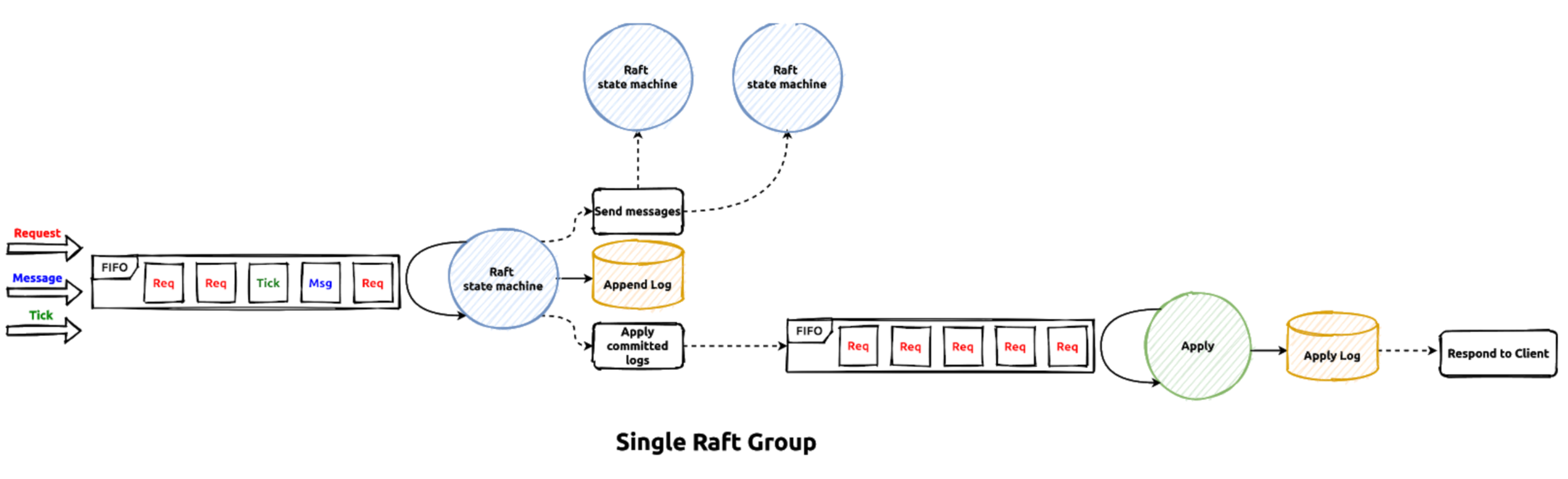
The writes generated by transaction commands will be sent to the raft peer message task queue first, then the raft batch system will poll each raft peer and handle these requests in the raft thread-pool. After all the raft logs are persisted on majority raft group members, they are regarded as commit. Then the correspond apply task be delivered to the apply worker pool to apply the actual write contents to the storage engine, after that the transaction command processing is considered successful and the callback will be invoked to response OK results to the RPC client.
Transaction Record In TiKV
In TiDB, a transaction is considered committed only if its primary key lock is committed successfully (if async commit protocol is not used). The actual key and value written into storage engine is in the following format:
| CF | RocksDB Key | RocksDB Value |
|---|---|---|
| Lock | user_key | lock_info |
| Default | {user_key}{start_ts} | user_value |
| Write | {user_key}{commit_ts} | write_info |
After prewrite, the lock correspond records for the transaction will be written into the storage. Read and write conflicts on the "locked" key will need to consider if it's safe to bypass the lock or it must try to resolve the encountered locks. As commit_ts is part of the stored key, there could be different historical versions for it, and GC is responsible to clean up all the old versions which will not be needed any more. GC mechanism will be introduced in another document.
Transaction Recovery
In TiDB, the transaction coordinator (in tidb-server) is stateless and it will not persist any information. If the transaction coordinator fails for example the tidb-server crashes, the transaction context in memory will get lost, and as the coordinator is gone the normal commit processing will stop. How to recover the transaction state and make a decision if it should commit or abort?
Actually, there is no special mechanism to recover the undetermined-status transactions, the recovery is done by other concurrent conflict transactions, or the conflict transactions will help decide the actual states of the undetermined-status transactions. The lock resolve process will be triggered if the current ongoing transaction encounters locks of other transactions doing reads or writes. The whole resolve process will be introduced in other documents in details.
Transaction Optimizations
Normally the transaction commit will need two phases, the prewrite phase and commit phase. Under certain circumstances transaction commit could be done in a single phase for example the generated transaction mutations could be processed by a single region leader. This optimization is called one-phase commit in TiDB.
The final transaction status is determined by the commit status of the primary key lock, so the response to the client has to wait until the primary key commit has finished. This wait could be saved using the async-commit protocol so the latency of commit processing could be reduced.
They will both be introduced other documents in details.
Summary
This section talks about the brief steps of transaction processing in the TiKV part, and related interfaces, implementations and optimizations.